Optimisation des calculs GPU/CUDA
Création d'applications en temps réel d'IA et de 3D avec une latence minimale grâce à l'accélération matérielle par GPU.

Différentes nuances du traitement par GPU
Nos solutions logicielles utilisent massivement le traitement parallèle en tirant parti des GPU. Au fil des années, nous avons appris à intégrer l'accélération matérielle GPU dans nos projets de nombreuses manières pour nous adapter à une large gamme d'exigences techniques : → Solutions de haut niveau : OpenVino, inférence GPU ONNX, TorchScript… → Solutions de bas niveau : noyaux CUDA, bibliothèques CUDA (cuSolver, cuDNN, TensorRT), LibTorch, OpenGL Compute, Vulkan.
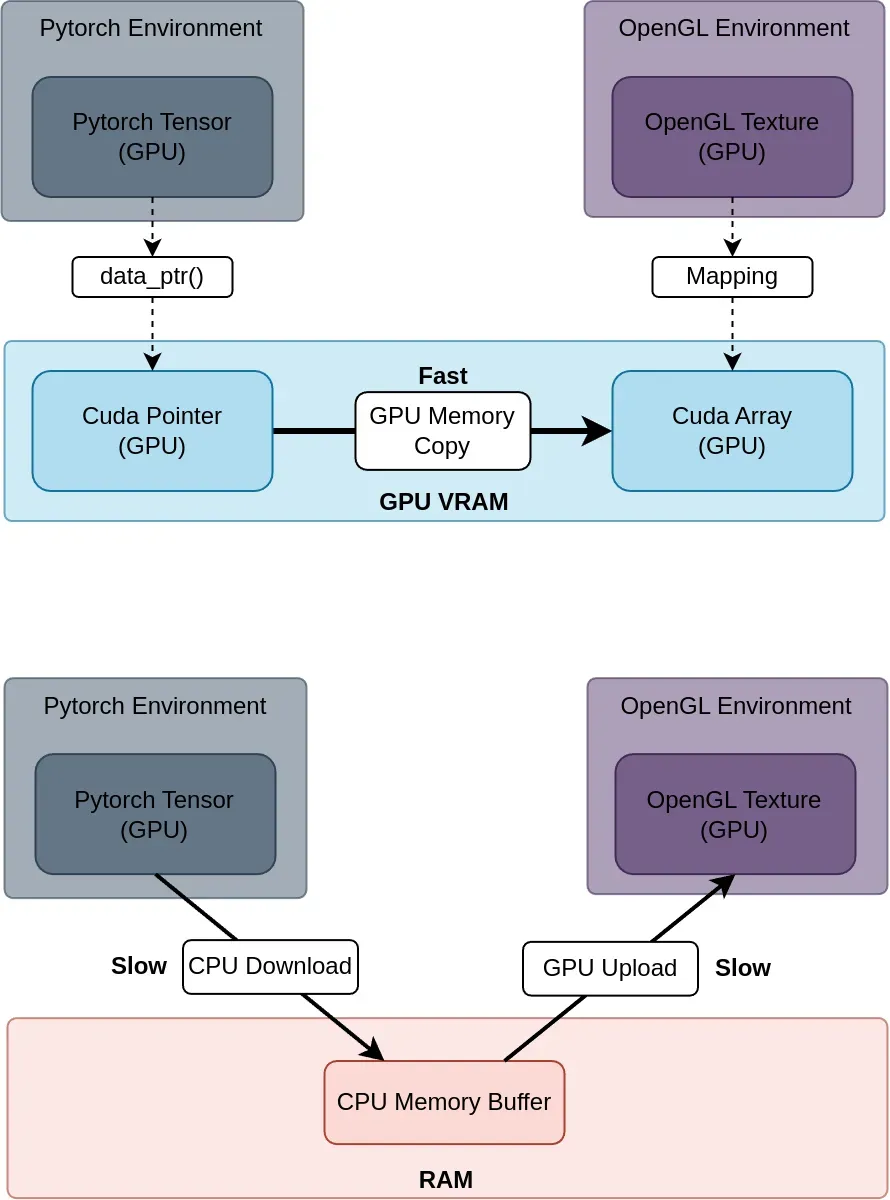
Transferts efficaces IA ⇔ Visualisation 2D/3D
Nos applications utilisent l'inférence de modèles d'IA et la visualisation 3D, et sont compatibles avec une large gamme de configurations système, telles que celles sans GPU dédié ou avec un ou plusieurs GPU. Nous avons conçu des méthodes de transfert efficaces compatibles avec les principaux frameworks d'IA (PyTorch, TensorFlow) et les bibliothèques graphiques couramment utilisées (OpenGL, Vulkan) afin d’offrir une expérience utilisateur rapide et fluide, même en cas de forte utilisation des ressources système.
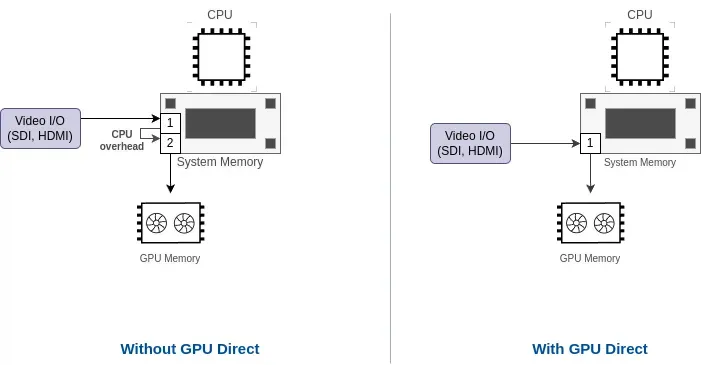
GPUDirect pour une I/O vidéo à faible latence
Nous avons intégré GPUDirect dans nos solutions logicielles pour réduire encore la latence lorsque cela est possible, et nous pouvons fournir des conseils pour sélectionner le matériel compatible (GPU, carte de capture vidéo…).
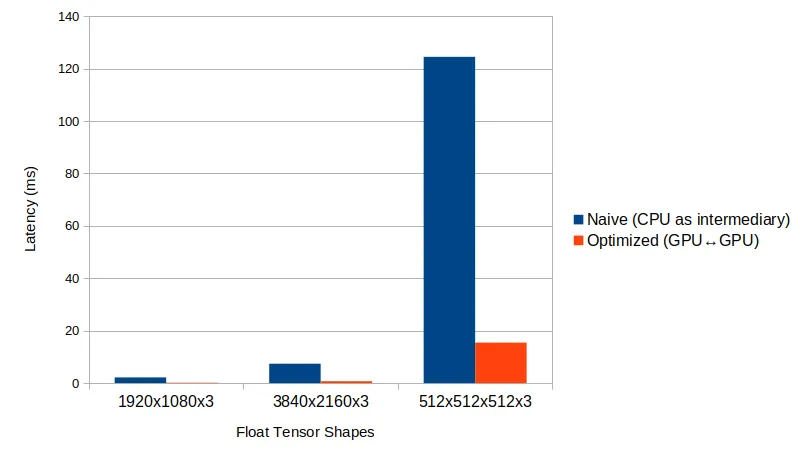
Cas réel d'amélioration de la latence/débit
Dans de nombreuses applications basées sur l'IA sans exigences strictes de faible latence, le CPU est généralement utilisé comme intermédiaire pour transférer les données de sortie du modèle IA vers le module de visualisation. Cependant, pour les applications où une faible latence est cruciale, nous pouvons proposer des solutions personnalisées qui contournent le CPU, permettant des transferts de données optimisés. Dans l'un de nos projets précédents, cette approche a permis de réduire la latence jusqu'à 15 fois.