GPU/CUDA Calculation Optimization
Crafting real-time AI and 3D applications with minimal latency using GPU hardware acceleration.

Different shades of GPU processing
Our software solutions often leverage parallel processing using GPUs. Throughout years of development experience, we learned to integrate GPU hardware acceleration inside our projects in many different ways, to adapt to a wide range of technical requirements: → High-level solutions: OpenVino, ONNX GPU inference, TorchScript… → Low-level solutions: Cuda kernels, Cuda libraries (cuSolver, cuDNN, TensorRT), LibTorch, OpenGL Compute, Vulkan.
Efficient AI to 2D/3D Visualization transfers
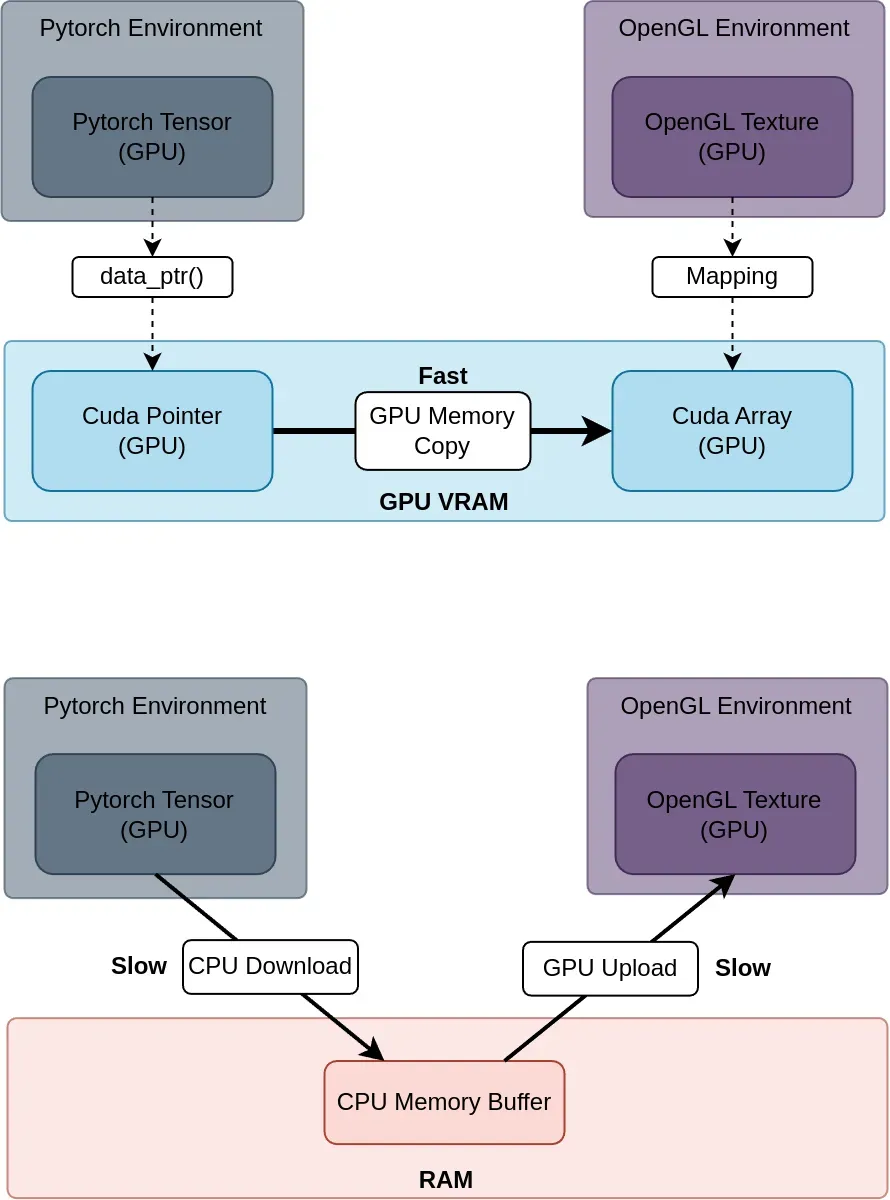
Our applications leverage AI model inference and 3D visualization, and perform seamlessly across a range of system configurations, including setups without a dedicated GPU, as well as single or multi-GPU environments. We've developed low-latency transfer methods optimized for leading AI frameworks such as PyTorch and TensorFlow, alongside popular graphics libraries like OpenGL and Vulkan. Our focus is on delivering a fast, responsive user experience, even under heavy computational or I/O loads.
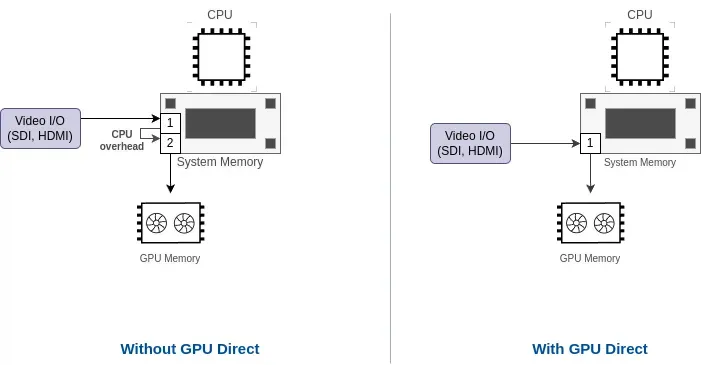
GPUDirect for low-latency video I/O
For extremely low-latency applications, we can integrate GPUDirect in a system solution to further reduce latency when possible, and can provide counseling for selecting compatible hardware (GPU, video capture card…)
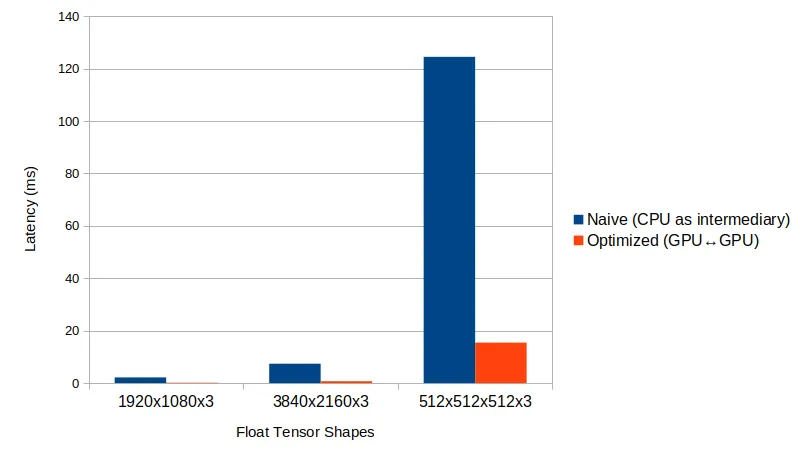
Real case of latency/throughput improvement
In many AI-based applications without strict low-latency requirements, the CPU is typically used as an intermediary to transfer the AI model output data to the visualization module. However, for applications where low latency is critical, we can offer customized solutions that bypass the CPU, enabling optimized data transfers. In one of our previous projects, this approach resulted in up to 15x lower latency.