GPU/CUDA計算最適化
GPUハードウェアアクセラレーションを使用して、リアルタイムAIおよび3DアプリケーションのGPU上での処理の最適化を実現します。

GPU処理のさまざまな形態
私たちはGPUを活用した並列処理を大規模に活用したソフトウェア開発技術を有しています。長年にわたり、さまざまな技術要件に適応するために、プロジェクト内でGPUハードウェアアクセラレーションを多様な方法で統合する技術を開発してきました。 → 高レベルソリューション: OpenVino、ONNX GPU推論、TorchScript… → 低レベルソリューション: Cudaカーネル、Cudaライブラリ (cuSolver、cuDNN、TensorRT)、LibTorch、OpenGL Compute、Vulkan。
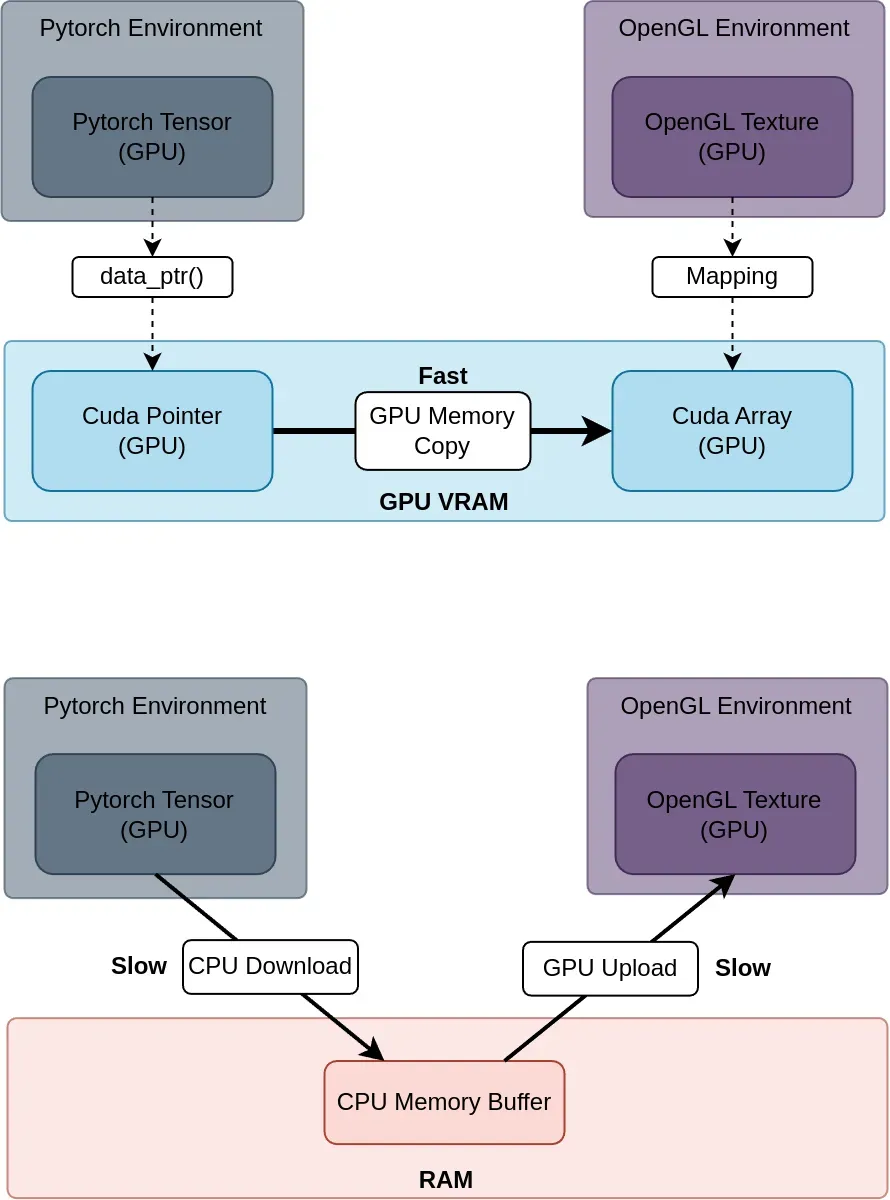
効率的なAI ⇔ 2D/3D画像可視化転送
私たちのアプリケーションは通常、同じGPU上で動作するAIモデルの推論と3D可視化によって駆動されています。 パフォーマンスとユーザーエクスペリエンスを大幅に向上させるため、主要なAIフレームワーク(PyTorch、TensorFlow)および一般的なグラフィックスライブラリ(OpenGL、Vulkan)と互換性のある効率的な転送方法を設計する技術を有しています。
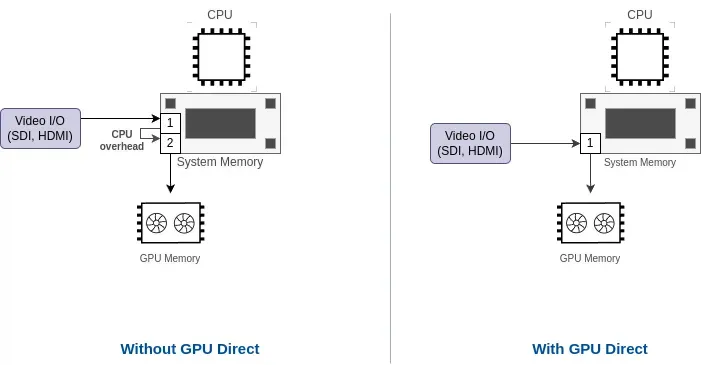
低遅延動画I/OのためのGPUDirect
可能な限り遅延をさらに削減するため、私たちのソフトウェアソリューションにGPUDirectを統合しました。また、互換性のあるハードウェア(GPU、ビデオキャプチャカードなど)の選択についての相談も承ります。
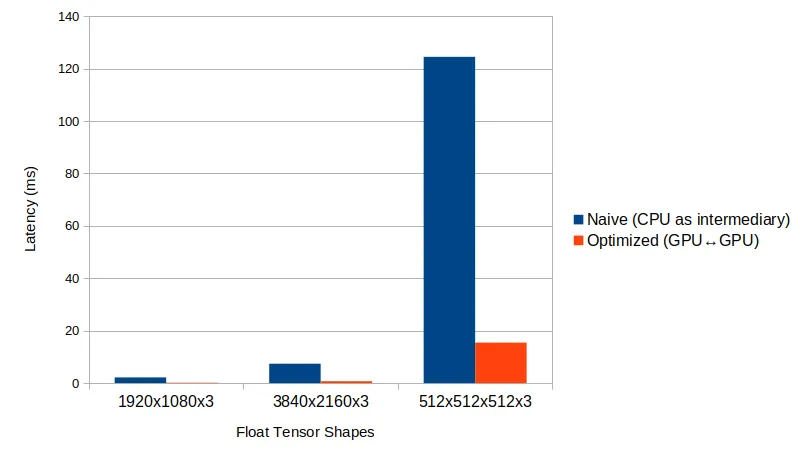
レイテンシー/スループット改善の実例
上のグラフは、Cudaを使用してPyTorchモデルの推論を計算し、OpenGLでレンダリングを行う基本的なPythonアプリケーションに最適化を適用した後に達成したレイテンシーとスループットの改善を示しています。